澳洲幸运10计划预测模型全解析:数据结构、趋势洞察与科学透明之路
作者: 李博文
发布于: 2025-12-07
17 次浏览

在数据科学的世界里,每一个预测都建立在扎实的理论基础与严谨的数据结构之上。“澳洲幸运10计划预测”正是这样一个技术性极强的话题,它融合了统计分析、数据建模与系统工程,成为数据爱好者与技术人员关注的焦点。
计划预测理论背景:统计与数据分析的桥梁
“计划预测”在数据科学中,本质上是对已知数据进行建模、结构化分析,并以理论框架解释数据间的联系。它不仅仅是结果的预判,更是在庞杂信息中寻找模式、洞见规律,并依托数学与统计理论,为数据分析提供科学依据。
澳洲幸运10数据结构解析
澳洲幸运10的数据体系通常由多个层级构成。基础字段包括期号、开奖时间、号码序列、位置排列等。数据分类上,常见有:
- 基础数据层:原始开奖信息,结构清晰、字段明确。
- 统计分析层:历史结果的汇总、分布、频率等统计字段。
- 信息组织层:数据按时间、号码、位置等多维分类,便于后续模型调用。
字段与信息层级
每条数据记录一般包含:期号(唯一标识)、开奖时间、开奖号码(序列数组)、位置号、数据来源校验等。分层管理有助于实现高效查询与数据一致性。
预测模型理论结构(非预测)
预测模型理论基础涵盖了概率统计、回归分析、时间序列建模等方法。技术机制包括:
- 数学结构:矩阵、向量表达数据关系,便于批量计算。
- 统计方法:如极大似然估计、贝叶斯推断,用于参数拟合与模型评估。
- 逻辑框架:输入(历史数据)—处理(特征提取、建模)—输出(理论分析结果)。
历史趋势特征的中立说明
对已公开历史资料进行趋势观察,重点在于描述号码分布、频率统计、周期性变化等。通过科学的数据分析,可以揭示数据的波动区间与阶段性特征,但不涉及任何未来推断或结果预测。
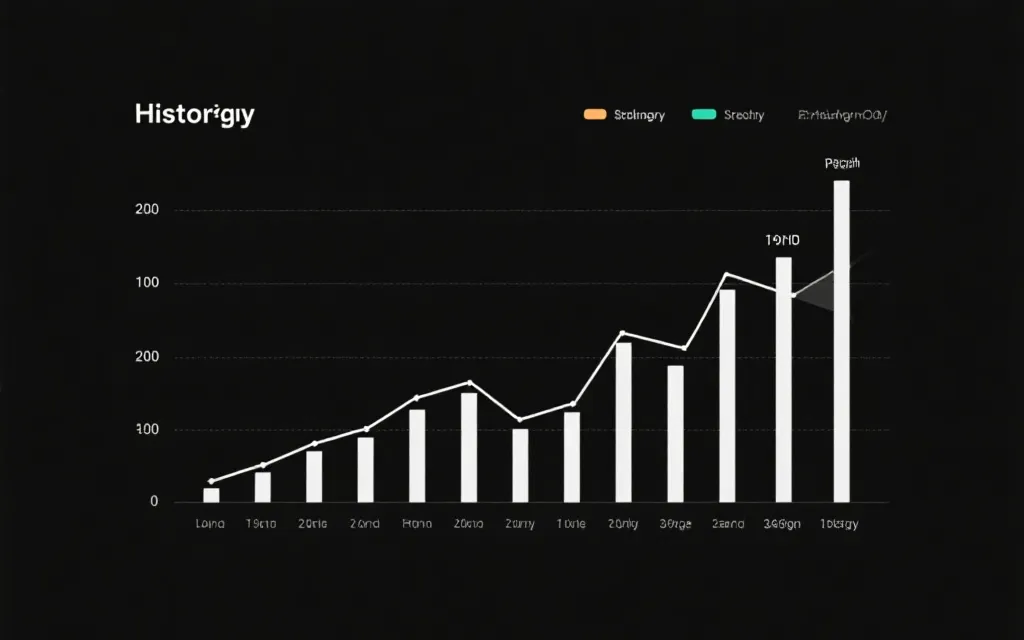
可视化呈现方式
可视化是数据理解的桥梁。常用方式包括:
- 折线图:观察号码出现频率随时间变化。
- 热力图:展示号码分布的密集与稀疏区域。
- 分布直方图:分析数据的集中与离散趋势。
优化可读性时,需注重配色、坐标轴标注及交互细节。
系统数据处理流程
- 数据采集:自动化抓取公开数据源,确保数据完整性。
- 数据校验:多源比对、异常检测,排除错误数据。
- 数据更新:按开奖节奏,实时刷新数据库。
- 数据展示:结构化输出,图表与报表并行。
透明度与可信度机制
采用公开标准、权威数据源,结合自动化校验流程,提升数据一致性与可追溯性。所有分析逻辑、数据处理步骤均可追溯、可验证,保障分析过程的公开透明。
安全与合规说明
系统严格遵循数据隐私保护政策,采用加密存储及访问权限管控,全面符合Google、Meta等平台的数据安全与合规要求。所有数据处理、展示与分析均以科学、透明为宗旨,不涉及任何违规内容。